Run pipelines defined in SQL from a dbt project on Apache Flink.

Support both batch processing and stream processing pipelines.
Utilize a wide range of data sources and sinks, including Kafka, HDFS, S3, RDBMS, and No-SQL databases.


Technologies Used
- Python
- Apache Flink
- dbt
Installation Process
- Please click here to read the installation process for dbt-Flink-adapter
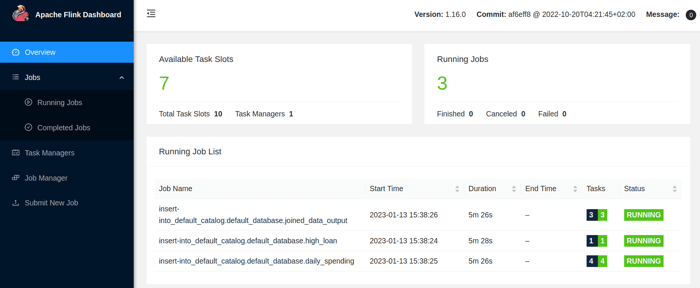
See it in Action
Model:
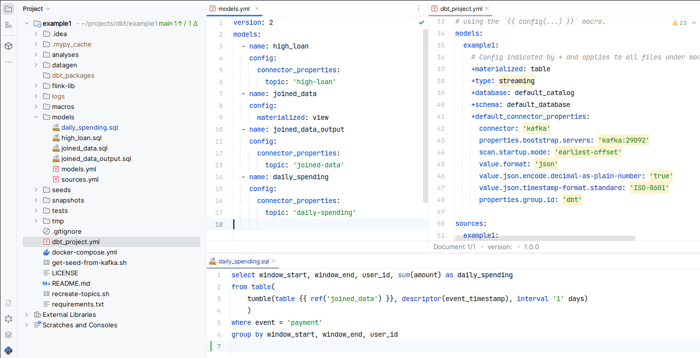
Execution:
Created Pipeline in Flink: